Le Pipelines in Azure Machine Learning
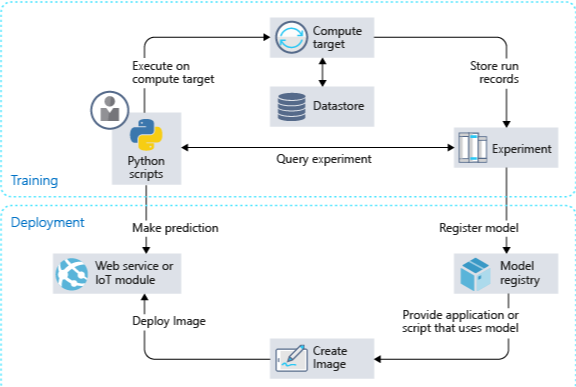
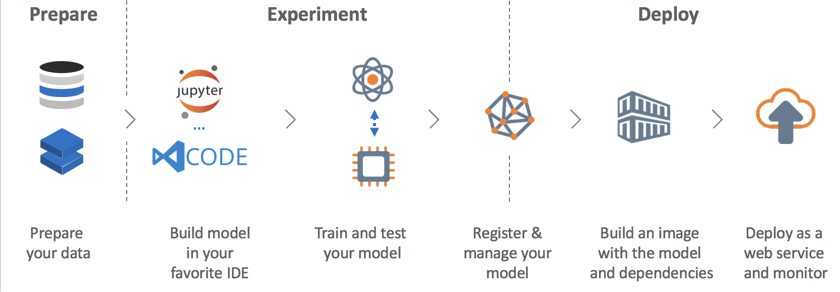
Machine learning pipeline
Le pipeline di machine learning (ML) sono utilizzate dagli scienziati dei dati per creare, ottimizzare e gestire i flussi di lavoro di machine learning.
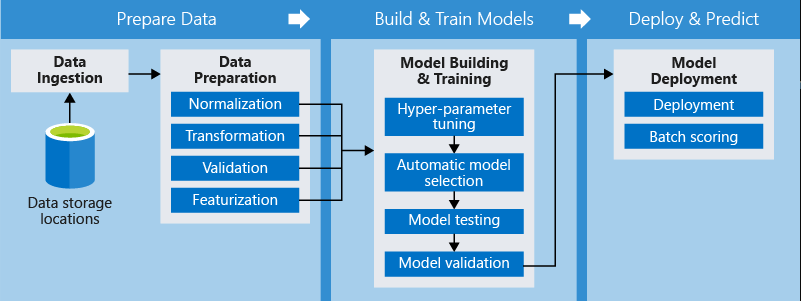
Una pipeline tipica prevede una sequenza di passaggi che coprono le seguenti aree:
- Preparazione dei dati, come normalizzazioni e trasformazioni
- Allenamento del modello, ad esempio ottimizzazione e convalida dei parametri iper
- Implementazione e valutazione del modello
Principali Vantaggi
L’utilizzo della pipeline in Azure machine learning comporta dei vantaggi:
Esecuzioni inattese
Pianifica alcuni passaggi per eseguire in parallelo o in sequenza in modo affidabile e incustodito. Poiché la preparazione e la modellazione dei dati possono durare giorni o settimane, ora puoi concentrarti su altre attività mentre la tua pipeline è in esecuzione.
Computazione mista e diversificata
Utilizzare più pipeline coordinate in modo affidabile su calcoli e archivi eterogenei e scalabili. Le singole fasi della pipeline possono essere eseguite su diversi target di calcolo, come HDInsight, GPU Data Science VM e Databricks, per utilizzare in modo efficiente le opzioni di calcolo disponibili.
Riusabilità
Le pipeline possono essere template per scenari specifici come riqualificazione e punteggio di lotto. Possono essere attivati da sistemi esterni tramite semplici chiamate REST.
Tracking and versioning
Invece di tracciare manualmente i percorsi dei dati e dei risultati durante l’iterazione, utilizzare l’SDK delle pipeline per denominare e eseguire in modo esplicito le origini dati, gli input e gli output e gestire separatamente script e dati per aumentare la produttività.
SDK di Azure Machine Learning per Python
L’SDK di Azure Machine Learning per Python può essere utilizzato per creare pipeline ML e per inviare e tracciare le singole esecuzioni della pipeline. Con le pipeline si può ottimizzare il flusso di lavoro con semplicità, velocità, portabilità e riutilizzo.
Quando si creano pipeline con Azure Machine Learning, è possibile concentrarsi su ciò che si conosce meglio, l’apprendimento automatico, piuttosto che l’infrastruttura.
L’utilizzo di passaggi distinti consente di rieseguire solo i passaggi necessari mentre si modifica e si verifica il flusso di lavoro.
Un passo è un’unità computazionale in cantiere. Il compito di preparare i dati può implicare molti passaggi tra cui, ma non solo, la normalizzazione, la trasformazione, la validazione e caratterizzazione.
Una volta che la pipeline è stata progettata, si rende necessario un fine-tuning intorno al ciclo di addestramento della pipeline.
Quando si esegue nuovamente una pipeline, si saltano i passaggi che non devono essere eseguiti, e viene eseguito solo quello che è stato cambiato.
Lo stesso paradigma si applica agli script invariati utilizzati per l’esecuzione.