Quando ci troviamo nella situazione di fare un esperimento di machine learning, ci troviamo, nel caso in cui non abbiamo una chiara idea a dover cercare in un mare di dataset. Scegliere poi il dataset corretto, o quello più “completo” è sempre un po’ difficoltoso. Questa difficoltà inizia, a volte, dall’idea che il dataset debba essere già in ordine. Al contrario molte volte il dataset deve essere preparato in base a quello che noi vogliamo predire.
L’analisi del dato all’interno di un dataset è di importanza fondamentale per tutto il processo di sviluppo del nostro modello.
Per questo si rende d’obbligo capire che il dataset per essere completo deve avere dei dati all’interno che seguano le seguenti regole.
- Devono essere rilevanti
- Devono essere connessi
- Devono essere accurati
- Devono essere sufficenti
- Devono rispondere ad una domanda specifica.
Ma cosa voglio dire esattamente queste affermazioni?
Cerchiamo di andare nello specifico:
I dati devono essere rilevanti
Avere dei dati rilevanti vuole dire avere dei dati che hanno un significato tra loro.
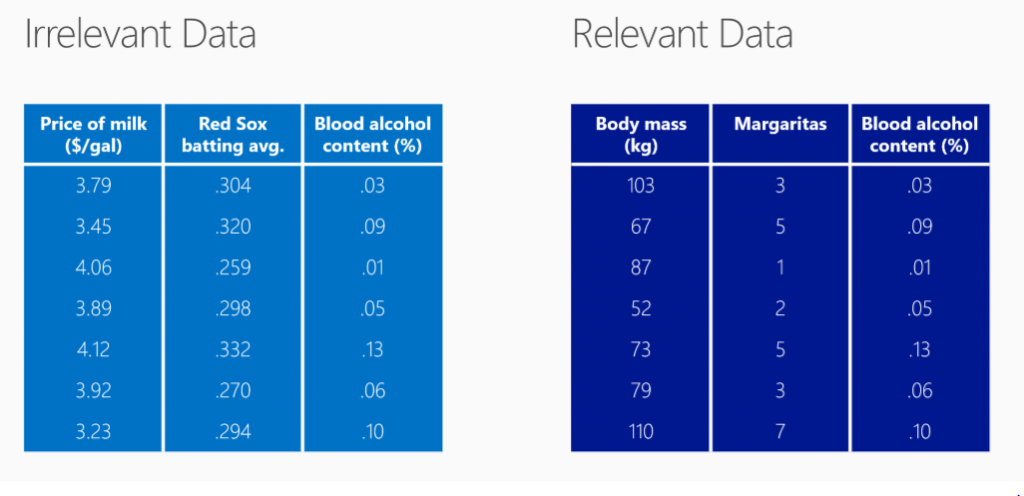
Come si può vedere dall’immagine è evidente che non esiste alcun tipo connessione tra le colonne della tabella di sinistra.
Al contrario dalla tabella di destra si evince chiaramente il collegamento tra le colonne.
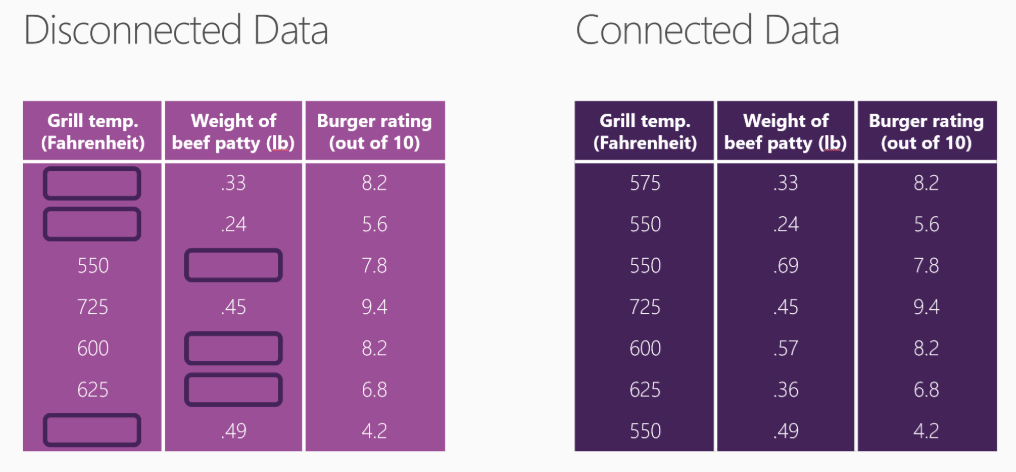
I dati devono essere connessi
I dati conessi sono importanti in quanto ci permettono di istruire correttamente il nostro modello per la futura predizione.
Per rendere la connessione sensata abbiamo necessità di una mole di dati, che possa permettere all’algoritmo che sceglieremo, di poter avere tutte le variabili necessarie per effettuare le sue trasformazioni e poter poi predire i dati.
I dati devono essere accurati
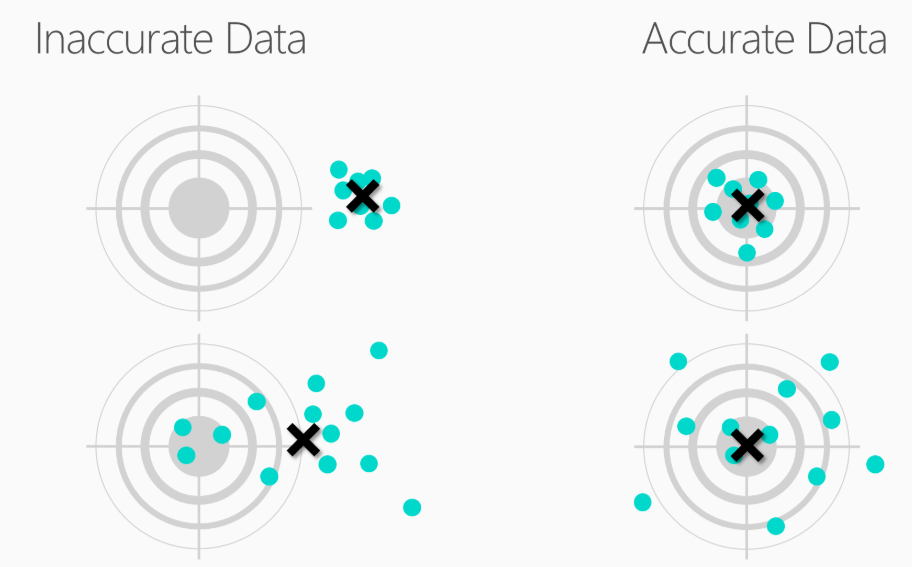
L’accuratezza dei dati è importantissima, in quanto ci permette di definire il nostro target e
Per quanto possa sembrare strano i dati in basso a destra sono accurati nonostante non siano precisi. L’accuratezza dipende dal fatto che il nostro bersaglio è centrato, quindi il nostro obbiettivo è raggiunto. Non conta la dispersione dei punti ma il centro del bersaglio.
I dati devono essere sufficenti
E’ evidente che per poter avere una predizione sensata, siano necessari molti dati. Non ne servono comunque nemmeno un milione. Dobbiamo istruire un modello quindi occorre la dimensione corretta, che varia in base alle casistiche che possiamo trovare.
Possiamo definire questo punto come la nitidezza di un quadro. Piu dati ho, più il quadro ha le pennellate più definite.

I dati devono rispondere ad una domanda specifica
E’ impensabile credere di avere dei dati e non avere chiaro la domanda a cui devono rispondere.
Questo per quanto ovvio possa sembrare è il punto focale dell’analisi dei dati. Più la domanda è generica meno potrò rispondere con i miei dati.
La domanda deve essere specifica per poter modellare il dataset seriamente.
Conclusione
I dati sono fondamentali e la loro analisi ovviamente diventa un lavoro serio e preciso. A maggior ragione nel caso in cui dovessimo manipolare la nostra base dati, dobbiamo renderci conto che queste regole ci possono aiutare a definire correttamente il nostro modello. Questo perchè:
Un modello non è altro che una storia semplificata dei dati.
Nei prossimi articoli vedremo qualcosa di interessante riguardo gli alle domande da porsi per arrivare alla definizione del nostro modello.